Aufbau einer Suchmaschine
Heute schon etwas gesucht? Hat man das Portemonnaie verlegt, kann sich die Suche durchaus als trickreich erweisen, wenn ohne Hilfe durch die Wohnung gestöbert wird. Auch im Web kann es zu stundenlangen Recherchen kommen. Zum Glück gibt es hier Suchmaschinen, die die Arbeit sehr erleichtern.
Aber wie funktionieren diese Suchmaschinen eigentlich? Die Suche nach dem Portemonnaie kann sich jeder mit seinem eigenen Suchen und Stöbern erklären. Doch die Funktionsweise von Google, Bing, DuckDuckGo oder Metager lässt sich nicht so leicht nachvollziehen.
Im Folgenden sollen deswegen die Hauptkomponenten einer Suchmaschine erklärt werden. Da sich die Grundprinzipien bei den verschiedenen Anbietern ähneln, liegt der Fokus im weiteren Verlauf auf Google. Für einen vergleichenden Blick empfiehlt sich z.B. das Kapitel „Aufbau von algorithmischen Suchmaschinen“ aus dem Buch „Web Information Retrieval“.
Ein kleiner Gesamtüberblick
Als erstes soll es eine kleine Übersicht zum Aufbau von Google geben. Die Abbildung stammt aus dem Text „The Anatomy of a Large-Scale Hypertextual Web Search Engine“ von Sergey Brin und Lawrence Page. Der Artikel beschreibt die Grundstruktur von Google.
Bei der folgenden Abbildung fällt der Pagerank ins Auge, der in den ersten Jahren von Google eines der wichtigsten Merkmale für den Aufstieg der Suchmaschine war. Heute ist der Pagerank weniger von Bedeutung. Zur Datenpflege und -speicherung existieren sehr viele Barrels (bzw. „Fässer“), in denen die Informationen der Webseiten gespeichert sind. Die drei wichtigsten Bestandteile Crawler, Indexer und Searcher werden im Folgenden näher beschrieben.
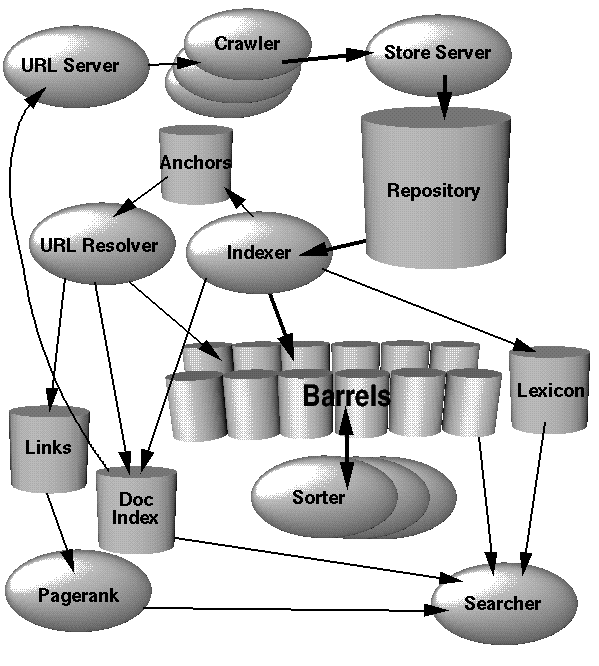
Abbildung aus „The Anatomy of a Large-Scale Hypertextual Web Search Engine“ von Brin und Page
Crawler
Zu Beginn muss jede Suchmaschine Webseiten finden, um damit einen Index aufzubauen. Das geschieht durch einen Crawler (oder auch Spider oder Robot). Der Crawler folgt Hyperlinks und findet dadurch weitere Webseiten. Der Prozess des Crawlings umfasst mehrere Phasen. Bevor er startet, muss eine Liste mit nicht besuchten Webseiten vorhanden sein. Diese Liste kann jederzeit mit weiteren URLs erweitert werden. Im nächsten Schritt besucht der Crawler die Seiten und lädt sie herunter. Ein Parser analysiert die Downloads und filtert u.a. die URLs heraus, die bereits in der Liste vorhanden sind. Die neu entdeckten Seiten werden in die Liste aufgenommen.
Im Fall von Google nehmen sich mehrere Crawler Links aus dem URL Server heraus. Die Daten werden heruntergeladen und zunächst an den Store Server übergeben. Der Store Server komprimiert und bearbeitet die Webseite, bevor sie an die Datenbank, dem Repository, geschickt wird. Der Indexer prüft die Seiten im Repository auf weitere URLs. Diese kommen dann wieder in den URL Server.
Der Crawler hat bei seiner Arbeit mit mehreren Hindernissen zu kämpfen. Dazu zählen u.a. Techniken wie Spider Traps und Cloaking, aber auch die allgemeine Struktur des Webs. Das Web ist zu groß und nicht gleichmäßig verlinkt. Deswegen ist eine durchgehende Indexierung nicht möglich.
Weitere Gründe für eine fehlende Indexierung können nicht interpretierbare Dateiformate, nicht lesbare Zeichen (z.B. hatte Google mindestens bis 2007 Schwierigkeiten chinesische Webseiten zu indexieren), die Suchmaschine hat die Seiten selbst aus dem Index genommen oder der Webseitenbetreiber verhindert den Zugriff des Crawlers. Die Crawler lassen sich über die Robots.txt, Metatags oder eine XML-Sitemap steuern. Dadurch können dem Crawler einige Inhalte verwehrt bleiben.
Der Crawler sorgt also dafür, dass Seiten in die Suchmaschine und in den Indexierungsprozess gelangen. Danach kommt der Indexer zum Einsatz.

Der Crawler auf der Suche nach neuen Seiten.
Indexer
Vor dem Indexer steht bei den meisten Suchmaschinen noch ein Parser. Er zerlegt die Seiten in ihre Bestandteile, z.B. wie oben erwähnt die Links oder Metadaten. Bei Google übernimmt der Indexer diese und weitere Aufgaben. Dazu zählen, das Repository zu durchsuchen und die Webseiten zu dekomprimieren.
Außerdem vergibt er für jede neue URL eine docID und für Terme die wordID. Mithilfe der wordID, beschreibenden Informationen und Rankingfaktoren wird ein Hit erstellt. Die docID und die Hits werden in den Barrels gespeichert. Mithilfe eines Forward Index werden diese Listen formatiert, also nach Dokumenten, die bestimmte Terme enthalten. Die wordIDs mit ihren zugehörigen Termen landen im Lexicon. Hier wird der Inverted Index angewandt, also die Liste mit Wörtern, die auf die Seiten referenzieren. Am Ende des Prozesses ist es dann möglich, schnell auf die Sammlung zuzugreifen und Dokumente wiederzufinden.
Weitere Ansätze der Sortierung sind z.B. Zitationsindices, Ngram-Indices oder (Suffix-)Bäume. Auf diesen einfacheren Methoden basieren die Algorithmen, die das Ranking zusammenstellen.
Searcher
Ab jetzt kommt der Nutzer der Suchmaschine ins Spiel. Vom Nutzer wird eine Anfrage formuliert und die Algorithmen müssen darauf reagieren. Die Ergebnisse müssen dann eine bestimmte Relevanz, Pertinenz (die subjektive Relevanz) und Nützlichkeit aufweisen. Die Maschine muss die Intention des Nutzers also verstehen.
Bei Google steht dafür der Searcher bereit. Die gestellte Suchanfrage wird analysiert. Das bedeutet sie durchläuft einen Parser, der die Zeichenkette nach Wörtern und Semantik untersucht. Die gefundenen Terme werden mit den im Lexicon enthaltenen wordIDs abgeglichen. Das System sucht dann in den Barrels nach den gefundenen IDs. In der ersten Google-Version gab es für diesen Schritt „short barrels“ und „full barrels“. Erstere konnten bereits viele Suchanfragen beantworten. Sie hatten eine bessere Kompression und Codierung, so dass sie schneller waren und weniger Speicherplatz benötigten. Wenn diese Barrels nicht für die Beantwortung der Anfrage ausreichten, kamen die „full barrels“ zum Einsatz. Anschließend wurden die Treffer mithilfe der Hit Lists ausgewertet und ein Ranking berechnet. Im besten Fall konnte dann die Nutzerintention befriedigt werden.
Fazit
Die wichtigsten Komponenten einer Suchmaschine sind also Crawler, Indexer und Searcher. Das Problem beim Aufbau einer Suchmaschine ist dabei, alles so effektiv wie möglich zu gestalten. Ein sinnvolles Ranking ist dabei genauso wichtig wie die Möglichkeit, abgespeicherte Information wiederzufinden. Um dabei das Web einigermaßen gut zu erfassen, benötigt die Suchmaschine Unmengen von Speicherplatz und effektive Crawler, die dafür sorgen, dass der Datenbestand vergrößert und aktuell bleibt.




