JavaScript SEO: Wie Google mit JavaScript-Websites umgeht und du deine Inhalte für die Suchmaschine aufbereiten kannst
Ein aktueller Trend sind JavaScript-Websites, die auf die Client-Side-Rendering-Methode setzen. Denn dadurch lassen sich dynamische Inhalte erzeugen, die sehr kurze Ladezeiten aufweisen. Doch Google und andere Suchmaschinen haben so ihre Probleme mit dieser Technik. Was Client-Side-Rendering bedeutet, woher die Probleme für die Bots kommen und wie man Google & Co. entgegenkommen kann, klären wir in diesem Artikel.
Google wird durchaus immer besser darin, JavaScript-Inhalte zu verstehen. War es vor einigen Jahren für die Suchmaschine noch völlig unmöglich selbst einfache Inhalte zu verarbeiten, die durch JavaScript-Bibliotheken wie jQuery generiert wurden, kommt Google damit mittlerweile klar. Doch die Google-Crawler stoßen nun auf eine neue harte Nuss, die geknackt werden muss: Websites, die komplett dynamisch auf Basis von JavaScript generiert werden.
An dieser Stelle kommt JavaScript SEO zum Einsatz. Denn natürlich willst du auch erreichen, dass Google deine auf JavaScript basierende Seite korrekt crawlt, indexiert und bestenfalls ganz vorne rankt. Besonders wichtig wird dies bei Websites, die auf Client-Side-Rendering setzen.
Wie Google Seiten crawlt und rendert
Bevor es an die Optimierung von JavaScript-Seiten geht, ist es wichtig zu verstehen, wie Google Website-Inhalte crawlt und indexiert – und wie dabei dynamische Inhalte gerendert werden. Der Indexierungsablauf für normale HTML-Inhalte ist dabei recht einfach:
- Der Google-Bot gelangt auf eine Seite und der Server spielt ihm direkt alle Inhalte der Seite im HTML-Quelltext aus. Dazu gehören Texte, Bilder, aber auch Links zu anderen internen wie externen Seiten.
- Diesen Links folgt der Google-Bot und analysiert auch den Quelltext dieser Seite, folgt den verlinkten Ressourcen und ggf. weiteren Links.
- Alle diese Inhalte werden vom Google-Bot an den Indexer geschickt, sodass die Seiten und Inhalte im Idealfall in Googles Suchindex aufgenommen und bei relevanten Suchanfragen ausgespielt werden können.
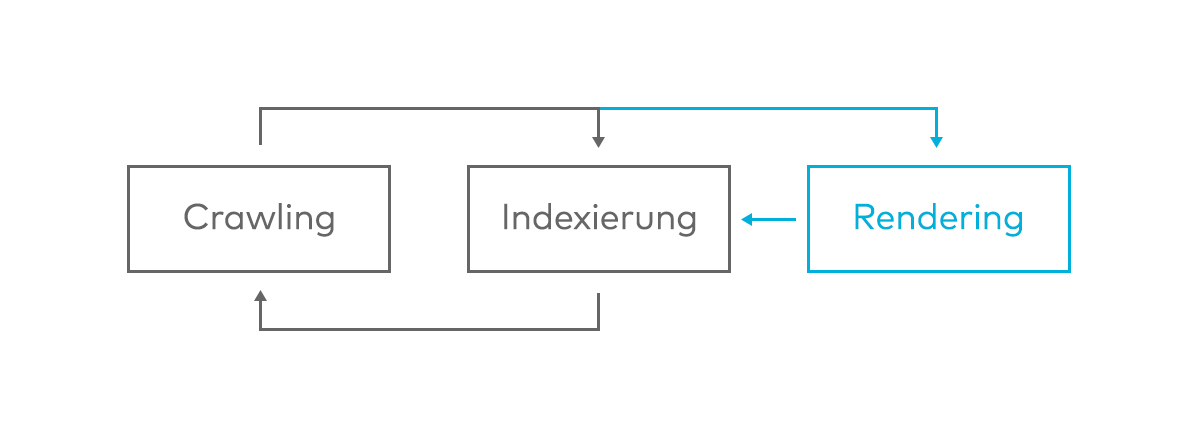
Kommen nun JavaScript-Inhalte hinzu, wird der Prozess um eine Phase erweitert. Dynamische Inhalte gibt der Crawler an eine Rendering-Stage weiter. Hier werden die dynamischen Inhalte ausgeführt und dann an den Indexer geschickt. Google spricht hierbei selbst von einer „second wave of indexing“. Da das Rendering sehr ressourcen- und kostenintensiv ist, hat Google den Prozess in eine separate Umgebung ausgelagert. Das führt auch dazu, dass JavaScript-Inhalte erst verzögert im Index landen.
Durch die Trennung will Google erreichen, dass statische Inhalte direkt gecrawlt und in den Index gelangen können, ohne erst auf die dynamischen Inhalte warten zu müssen, die JavaScript benötigen. Diese werden dann einfach nachgereicht. Google kann also durchaus JavaScript-Inhalte erkennen. Es kann nur länger dauern, bis diese im Index landen. Eine genaue Zeitangabe dafür ist jedoch nicht möglich. Laut Google kann dies sehr schnell gehen, aber auch mal Tage oder sogar Wochen dauern.
Was sind JavaScript-Seiten? Server Side Rendering, Client Side Rendering und andere böhmische Dörfer
Vermutlich gibt es heutzutage kaum eine Website, die ohne JavaScript auskommt. Denn Skript-Bibliotheken wie jQuery sind sehr weit verbreitet und für Effekte auf Websites durchaus nützlich. Doch nur weil eine Seite JavaScript einsetzt, fällt diese nicht gleich in die Kategorie JavaScript-Seite. Solange der Hauptinhalt der Seite ohne JavaScript nutzbar und erkennbar ist, handelt es sich um eine ganz normale Website.
Überprüfen lässt sich dies recht einfach: öffne die gewünschte Seite, mache irgendwo einen Rechtsklick und wähle dort Seitenquelltext anzeigen aus. Wenn dir eine lange Seite mit allerhand HTML-Elementen angezeigt wird, handelt es sich dabei um eine reguläre HTML-Seite.
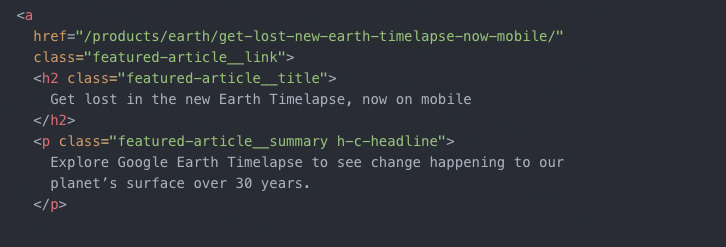
Das obere Beispiel stammt aus dem HTML-Code von Googles offiziellem Blog. Erkennbar sind deutlich einzelne HTML-Elemente. Insgesamt umfasst der Quellcode rund 2.400 Zeilen. Sieht der Quellcode einer Website so aus, spricht man vom Server-Side-Rendering. Das heißt, der Server, auf dem die Seite liegt, spielt alle Inhalte und Ressourcen für den Nutzer und den Suchmaschinen-Bot aus.
Dem gegenüber steht das Client-Side-Rendering. Hierbei rufst du als Nutzer primär eine oder mehrere JavaScript-Dateien auf. Im Quelltext der Website steht nicht viel mehr als der Verweis auf diese JavaScript-Dateien. Der Rest passiert dir bei dir als Nutzer: auf Basis des JavaScripts werden die einzelnen Inhalte generiert. Du lädst also nur ein Gerüst herunter, dass dann bei dir mit Inhalten befüllt wird. Solche Seiten versteht Google als JavaScript-Seiten.
Client Side Rendering ist im Quelltext recht einfach zu erkennen: meist sind hier nur wenige Zeilen HTML-Code vorhanden, in denen entsprechende JavaScript-Dateien geladen werden. Beispielsweise könnte der Quelltext solch einer reinen JavaScript-Seite so aussehen:
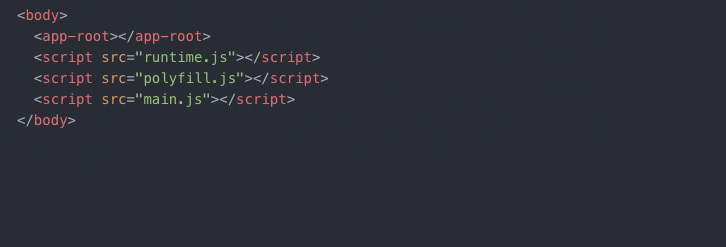
Erkennbar sind darin keine weiteren HTML-Attribute. Ein deutliches Zeichen dafür, dass hier vor allem auf JavaScript gesetzt wird. Das Problem für die Suchmaschinenoptimierung liegt aber auch genau darin: dadurch, dass diese Websites kaum HTML-Quelltext besitzen, können Suchmaschinen-Crawler auch recht wenig Inhalte vorfinden, die sie indexieren und für ein Ranking mit einbeziehen können. Dies kann erst erfolgen, wenn die Inhalte – wie oben beschrieben – an die Rendering-Stage geschickt und dort verarbeitet wurden.
Dynamic Rendering nutzen um Google entgegen zu kommen
Um Inhalte dennoch schnell den Suchmaschinen-Crawlern zur Verfügung zu stellen, rät Google zu einem Dynamic Rendering. Dadurch wird dem Nutzer die Website weiterhin via Client-Side-Rendering ausgespielt. Für Crawler beispielsweise werden jedoch bereits vom Server gerenderte Inhalte ausgespielt. Sie sind also im Zweifelsfall nicht topaktuell, sondern stammen aus dem Cache. Das Dynamic Rendering ist jedoch sehr ressourcenintensiv. Daher empfiehlt Google eine Auslagerung des Renderings auf einen zweiten Server.
Dynamic Rendering lässt sich durch eigene Programmierungen umsetzen, aber auch durch externe, kostenpflichtige Dienste. In seiner Developer-Hilfe nennt Google unter anderem die Tools Puppeteer, Rendertron und prerender.io. Ob eine interne oder externe Lösung Sinn macht, ist dabei von Projekt zu Projekt unterschiedlich und vor allem vom Budget sowie dem zu erwartendem Aufwand abhängig. Wenn der Google-Bot die JavaScript-Inhalte gut erkennen kann, ist ein Dynamic Rendering womöglich nicht notwendig.
Laut Google eignet sich Dynamic Rendering vor allem für
- große Websites, die ständig neue Inhalte dazu bekommen
- Websites, die auf neue Browser-Features setzen, welche erst ab Chrome 41 unterstützt werden
- Websites mit einer starken Präsenz in sozialen Medien, bei denen es wichtig ist, dass die sozialen Netzwerke auf die Inhalte der Website zugreifen können (z.B. beim Teilen von Seiten)
Dadurch, dass dem Nutzer und dem Crawler unterschiedliche Inhalte ausgespielt werden können – denn die Inhalte für den Crawler stammen aus dem Cache – besteht natürlich eine gewisse Cloaking-Gefahr. Dem Crawler könnten also besonders optimierte Inhalte ausgespielt werden, die der Nutzer aber gar nicht sieht. Auch mit topaktuellen Inhalten sieht es schwierig aus, denn Google erhält immer nur eine Version aus dem Cache.
Universal JavaScript als Hybrid für Nutzer und Crawler
Eine weitere, noch recht neue Methode zum Ausspielen von JavaScript-Seiten ist der Einsatz von Universal JavaScript. Hierbei wird das JavaScript vom Server und vom Client ausgespielt. Dem Client wird dabei ein bereits gerendeter HTML-Quelltext ausgespielt, während zusätzlich weiterhin dynamische Inhalte generiert werden können. Der Crawler erhält also sofort alle wichtige Inhalte, während der Nutzer durch die Client-Side-Rendering-Aspekte dennoch dynamische und schnell ausgespielte Inhalte nutzen kann. Der Google-Bot muss also nicht erst auf die Rendering-Stage warten.
Aus SEO-Sicht ist Universal JavaScript ein guter Mittelweg: der Crawler erhält sofort alle SEO-relevanten Inhalte – angefangen bei den Meta-Daten, weiter über Überschriften, Texte und Links – und kann diese somit direkt an den Indexer schicken. Der Nutzer erhält dennoch sehr schnell die durch JavaScript erzeugten Inhalte.
Rendering-Fehler checken
Um zu überprüfen, ob Google mit deiner JavaScript-Website zurechtkommt, empfiehlt Google selbst den Mobile-Friendly-Test. Denn hier zeigt dir Google den gerenderten Quelltext, samt eines Screenshots der gerenderten Seite an. Auch eventuelle Fehler in der JavaScript-Konsole werden ausgespielt, die dir bei der Ursachenforschung bei eventuellen Rendering-Fehlern helfen können.
Zudem gibt dir die Google Search Console einen Überblick, ob und welche Seiten erfolgreich im Index gelandet sind. Zeigt Google hier keine Seiten im Index an, ist dies ein klares Zeichen dafür, dass der Crawler Probleme damit hat, deine Seite erfolgreich an den Indexer zu schicken. Dann heißt es: überprüfen, wo es Fehler gibt.
Suchmaschinen und JavaScript
Die hier beschriebenen Lösungsmöglichkeiten beschränken sich alle auf Google. Das hat einen guten Grund, der eigentlich gar nicht so gut ist: wie ein Experiment von Moz aus dem Jahr 2017 zeigt, ist Google bislang die einzige große Suchmaschine, die über mit JavaScript-Inhalten klarkommt. Einzig und allein Ask.com kann auch mit JavaScript-Inhalten umgehen. Für Bing gibt es mittlerweile erste Anzeichen, dass auch hier teilweise JavaScript verarbeitet werden kann.
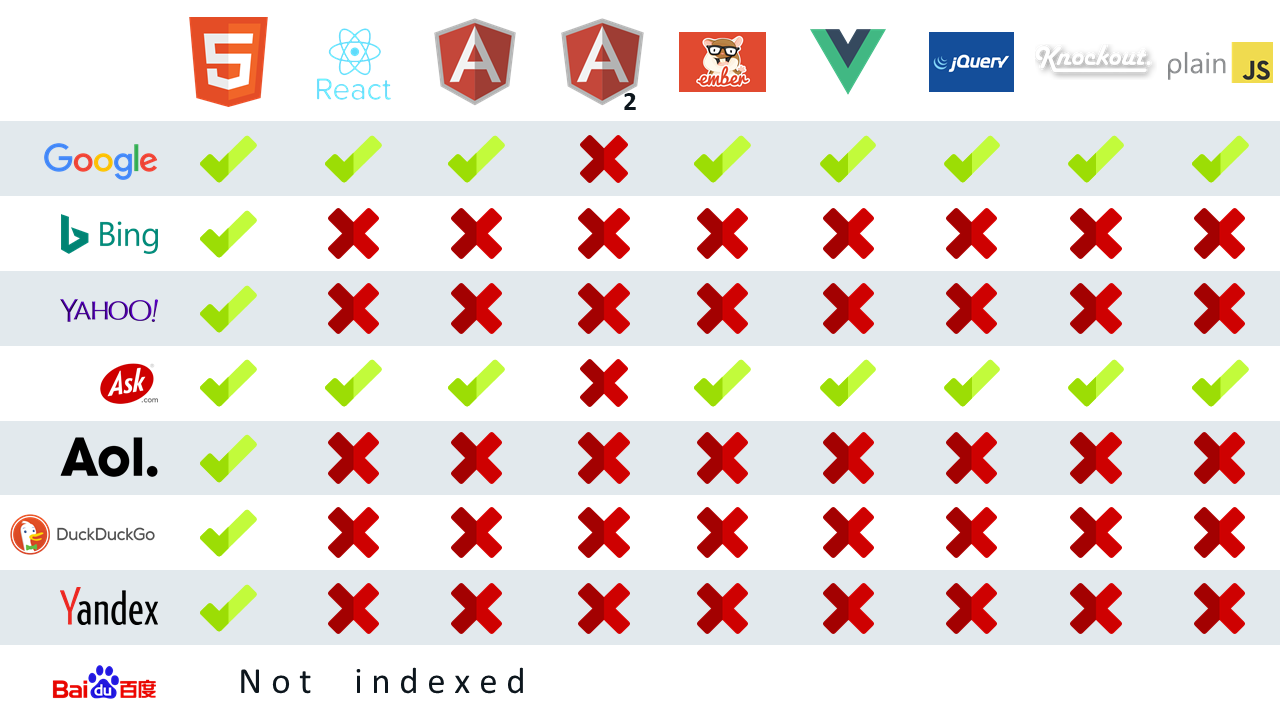
Nun werden in Deutschland rund 9 von 10 Suchanfragen über Google getätigt, sodass man meinen könnte, die restlichen Suchmaschinen seien zu vernachlässigen. International schwankt Googles Marktanteil je nach Region jedoch sehr stark. Vor allem internationale Projekte sollten also sehr gut überlegen, wie JavaScript-Seiten effizient für Suchmaschinen aufbereitet werden können.