SEO Auslese Oktober 2020
Google hat im Oktober ein großes Update für November angekündigt. Einzelne Textpassagen auf Webseiten sollen stärker berücksichtigt werden und vermehrt in den Rankings auftauchen, davon werden sieben Prozent der Rankings betroffen sein. Eine Untersuchung der Ranking-Einflüsse von Google-My-Business-Elementen zeigte, dass der Unternehmensname und die Wahl der Kategorie die stärksten Einflüsse auf das Ranking haben. Viele weitere spannende Themen zur SEO-Branche und der Google-Suche findet ihr wie gewohnt in unserer SEO Auslese vom Oktober 2020.
News der Suchmaschinen
Google versteht bald einzelne Textpassagen auf Webseiten viel besser
Im November 2020 wird es ein größeres Algorithmus-Update geben. Google will demnach nicht mehr ganze Seiten für Suchanfragen berücksichtigen, sondern verstärkt auch einzelne Textpassagen. Das soll rund sieben Prozent aller Suchanfragen betreffen. Die Relevanz von Suchergebnissen soll auf diese Weise weiter steigen, da Google nun feststellen kann, ob ein Thema nur oberflächlich behandelt oder in einzelnen Textpassagen näher erörtert wird. Es handelt sich hier nicht um eine Änderung in der Indexierung, da auch nach dem Update weiterhin die ganze Website indexiert wird, sondern eher um eine Änderung der Rankings, da einzelne Textpassagen nun besser verstanden werden. Ausgerollt wird dieser neue Rankingfaktor bis zum Ende des Jahres erstmal in den USA.
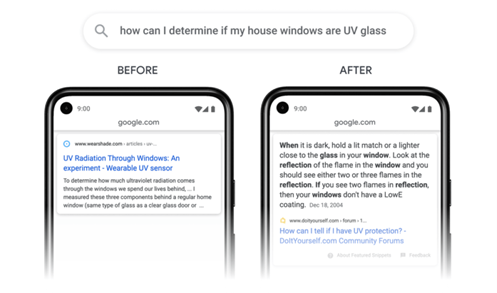
Ein Beispiel von Google zeigt, wie dieses Update wirkt. Bei der sehr spezifischen Suchanfrage „wie kann ich herausfinden, ob meine Hausfenster aus UV-Glas bestehen“ wird aktuell eine Website als bester Treffer angegeben, die das Thema sehr holistisch beleuchtet. Nach dem Update wird ein Featured Snippet mit der relevanten Textpassage ausgegeben.
Google warnt davor, in einen Optimierungswahn zu verfallen. Bereits gut strukturierte Inhalte auf Webseiten sind von dem Update nicht betroffen. Webseiten mit einer schwer zu analysierenden Struktur können dagegen für das Update weiter optimiert werden. Das bedeutet: Texte in logische Absätze gliedern, Überschriften / Zwischenüberschriften, Stichpunkte usw.
Google erklärt, wie die Indexierung via Caffeine erfolgt
In der neusten Episode von Search of the Record haben die Google Webmaster John Müller, Martin Splitt und Gary Illyes interessante Einblicke in das Indexierungssystem Caffeine von Google gegeben. Caffeine geht dabei schrittweise vor:
Schritt 1 Ingesting:
Alle Daten, die vom Google Bot ausgelesen wurden, werden aufgenommen. Die Daten werden dann mit Hilfe des Protocol Buffer serialisiert, sie werden also in strukturierten Daten abgebildet.
Schritt 2 Conversion:
In diesem Schritt werden HTML-Codes normalisiert, sie werden also von Fehlern bereinigt. Aber auch das Umwandeln anderer Datenformate, wie zum Beispiel PDF-Daten und Word-Dokumente, in einen HTML-Code gehört dazu. Hier wird mit Hilfe eines HTML-Lexer (auch Parser genannt – ein Programm, dass Informationen in ein geeigneteres Format umwandelt oder zerlegt) der Code in einzelne Teile zerlegt, in sogenannte Tokens. Außerdem werden Überschriften auf ihr Styling hin überprüft und miteinander verglichen. Zum Schluss wird nach den Meta Tags geschaut. Steht eine Seite z.B. auf noindex, wird die weitere Verarbeitung abgebrochen.
Schritt 3 Collapsing:
In diesem Schritt werden die Fehlerseiten überprüft und validiert, wenn z.B. 404-Fehlerseiten den Status Code 200 senden. Caffeine nimmt dazu einen Abgleich der Fehlerseite vor und vergleicht diesen mit vielen anderen exemplarischen Fehlerseiten, um festzustellen, ob es sich tatsächlich um einen Fehler handelt.
Einen weiteren wichtigen Hinweis geben sie zum <head>-Bereich. Wird ein Tag gefunden, wie zum Beispiel <div> oder <span>, der im <head> nicht hingehört, schließt Caffeine alle darauffolgenden Infos aus und geht sofort zum <body> über. Dadurch können wichtige Infos verloren gehen bzw. gar nicht erst berücksichtigt werden.
Insgesamt haben die drei Google Webmaster die Funktionsweise sehr vereinfacht erklärt, da der Prozess in Realität viel detaillierter sein wird. Dennoch gibt es einen guten Einblick und zeigt, wie wichtig saubere Quellcodes und gut strukturierte Daten sind.
Große Chance für Nicht-AMP-Seiten dank Core Web Vitals
Google hat bestätigt, dass mit der Umsetzung der Core Web Vitals (CWV) als Rankingfaktor Nicht-AMP-Seiten an Stellen der Suchergebnisse auftauchen werden, die eigentlich nur für AMP-Seiten vorgesehen waren: Top Stories in der mobilen Suche, bestimmte Karussellergebnisse, große Bilder bei AMP-Suchergebnissen. Bedingung ist, dass die Webseiten-Werte für CWV gut sind und somit mit AMP-Seiten mithalten können. Für strategische Überlegungen macht es also Sinn zu schauen, wie gut man die CWV-Faktoren optimieren kann und ob das für Google ausreicht.
News der Suchmaschinen kurz & knapp
- Der neue Rankingfaktor Core Web Vitals greift auf Daten von vergleichbaren Seiten oder der gesamten Website-Performance zurück, wenn zu wenig Daten für die einzelne URL zur Verfügung stehen.
- Googles Webmaster John Müller hat nun das aktuelle Datum für den kompletten Umstieg auf den Mobile First Index angekündigt: Es wird im März 2021 soweit sein.
- Design und Layout einer Website können sich aufs Ranking auswirken und das selbst dann, wenn sich nur das Layout ändert, sämtlicher Content und Code auf der Website aber gleichbleibt. Ein Grund mehr, nochmal nachzuschauen, ob Google die Websites auch wirklich rendern kann. Mit der Funktion „Abruf wie durch Google Bot“ in der Search Console kann man überprüfen, ob Google auch wirklich alle Inhalte lesen und vollständig darstellen kann.
- Sollte man Verlinkungen auf soziale Medien von der eigenen Website auf nofollow setzen? Google Webmaster John Müller hat klar dazu gesagt, dass man solche Links nicht unbedingt anders behandeln sollte als Verlinkungen zu empfohlenen Artikel. Man solle sich die Frage stellen, ob es sich bei dem Link um eine Empfehlung oder um eine Referenz handele. Wenn das der Fall ist, dann wäre ein nofollow eine verwirrende Botschaft.
Local SEO News
Unternehmensname in Google My Business hat stärksten Ranking-Einfluss
Moz hat getestet und herausgefunden, welche Felder im Google My Business einen Einfluss auf die Rankings haben:
- Platz 1: Unternehmensname
- Platz 2: Kategoriewahl
- Platz 3: Wahl der URL
- Platz 4: Bewertungen
Allgemein haben die Felder, die Infos zum Unternehmen bereitstellen, einen Einfluss auf die Rankings. Dazu zählen auch Beschreibungen und die Beiträge-Funktion. Q&A Feature, Attribute, Fotos, Features zu Produkten und Leistungen haben keinen Einfluss. Das bedeutet aber nicht, dass man diese vernachlässigen sollte. Letztendlich tragen sie dazu bei, die Interaktionsrate zu steigern, da BesucherInnen auf einen Blick viele Informationen erhalten. Mal ehrlich, wer hat das letzte Mal auf einen Eintrag geklickt, der keine Bilder enthielt?
Anruf-Historie im Google My Business
Google My Business testet jetzt eine Anruf-Historie aus, in der man sehen kann, inwieweit NutzerInnen über die Google-Suche das Unternehmen angerufen haben. Diese Option kann aktiviert und deaktiviert werden. Die Anrufe werden 45 Tage lang in der Google My Business App geloggt. Aktuell wird das Feature in den USA getestet.
Branchen Insights
Emojis in den Google-Suchergebnissen
Sistrix hat eine interessante Analyse durchgeführt, inwieweit Emojis in den Snippets aufgegriffen werden. Google betrachtet dabei Title und Description unterschiedlich, wobei in der Description mehr möglich ist. Bei den untersuchten Snippets wurden im Title am häufigsten 🥇, 🤑 und 🥾 verwendet. In der Description zeigt Google am meisten ✅, ❌ und ⭐ an, wobei als normales Sonderzeichen ✓ und diverse Pfeile am meisten aufgegriffen werden.
Sistrix hat eine große Liste veröffentlicht, welche Emojis und Sonderzeichen noch funktionieren.
Branchen News kurz & knapp
- MOZ hat einen umfangreichen Artikel zur Erstellung einer qualitativ hochwertigen FAQ-Seite veröffentlicht. Angefangen bei der Recherche der richtigen Fragen wird auf die Verlinkungsstrategie und weitere Optimierungshebel eingegangen.
- Google zeigt auf YouTube eine einstündige Dokumentation über die Funktionsweise der Suche. Die Doku heißt „Trillions of Questions, No Easy Answers: A (home) movie about how Google Search works” und beschäftigt sich mit den aktuellen Herausforderungen (Buzzwords wie „E-A-T“, „BERT“ und „AI“) sowie die bisher erreichten Meilensteine. Es lohnt sich, reinzuschauen.
- Bing hat in seinem SEO-Tool Bing Webmaster Tools einen überarbeiteten Site Explorer ausgerollt. Für die gesamte Website, aber auch einzelne Verzeichnisse, können Fehler, geblockte URLs und weitere Informationen schnell und übersichtlich eingesehen werden.





Hallo Nico, danke für die Zusammenfassung zu den wichtigsten Oktober News. Ich würde aber bei den Branchen Insights noch einiges ergänzen, insbesondere was die Meta Daten angeht und die Emoji Nutzung. Wichtig zu erwähnen, wäre zum Beispiel, dass Google bei den Emojis keine überschneidungen anbietet, d.h. nicht alle Emojis die beim Meta Titel verwendet werden, würden bei der Meta Description funktionieren. Ich würde auch noch ergänzen, dass Emojis in den Titel zu bekommen, keine einfache Aufgabe ist, insbesondere im Vergleich mit Text Snippets. Du könntest hier auch mehr zu den Meta Tags lesen und vielleicht einige Ergänzungen machen: https://www.onlinesolutionsgroup.de/blog/glossar/m/meta-tags/